Door Marc van Oostendorp
Vandaag is de Grote Taaldag, een dag dat heel taalkundeminnend Nederland normaliter naar Utrecht afreist omdat er dan vele, vele lezingen gegeven mag worden: alle leden die dag willen mogen iets vertellen, er is geen selectie vooraf en daardoor kun je er ook kort iets vertellen over waar je je mee bezig bent, ook al is dat nog niet af.
Ik ga met mijn collega Mirella De Sisto iets zeggen over ons onderzoek naar het vermijden van rijm. In stijlboeken wordt al heel lang opgemerkt dat je in proza beter rijm kunt vermijden. Het is ook niet lastig na te voelen; als je zonder het te bedoelen in proza twee woorden rijmen laat ligt al snel een rode pen paraat. Het heeft iets potsierlijks al is niet helemaal duidelijk waarom. Ja, “omdat die klankeffecten teveel afleiden”, maar waarom is dat zo, waarom kun je die klankeffecten dan niet negeren? En waarom heeft specifiek rijm (en metrum) dat effect, er zijn toch ook andere klankeffecten?
Heuveltjes
Nu zijn we nog lang niet zo ver dat we ook maar het begin van een antwoord hebben op deze vragen. Eerst maar eens vaststellen of het ook echt zo is, of die adviezen worden opgevolgd. Daarvoor hebben we gebruik gemaakt van de verzameling van 1100 ingescande (streekromans) van Ewoud Sanders waar ik vorig voorjaar ook al mee gespeeld heb.
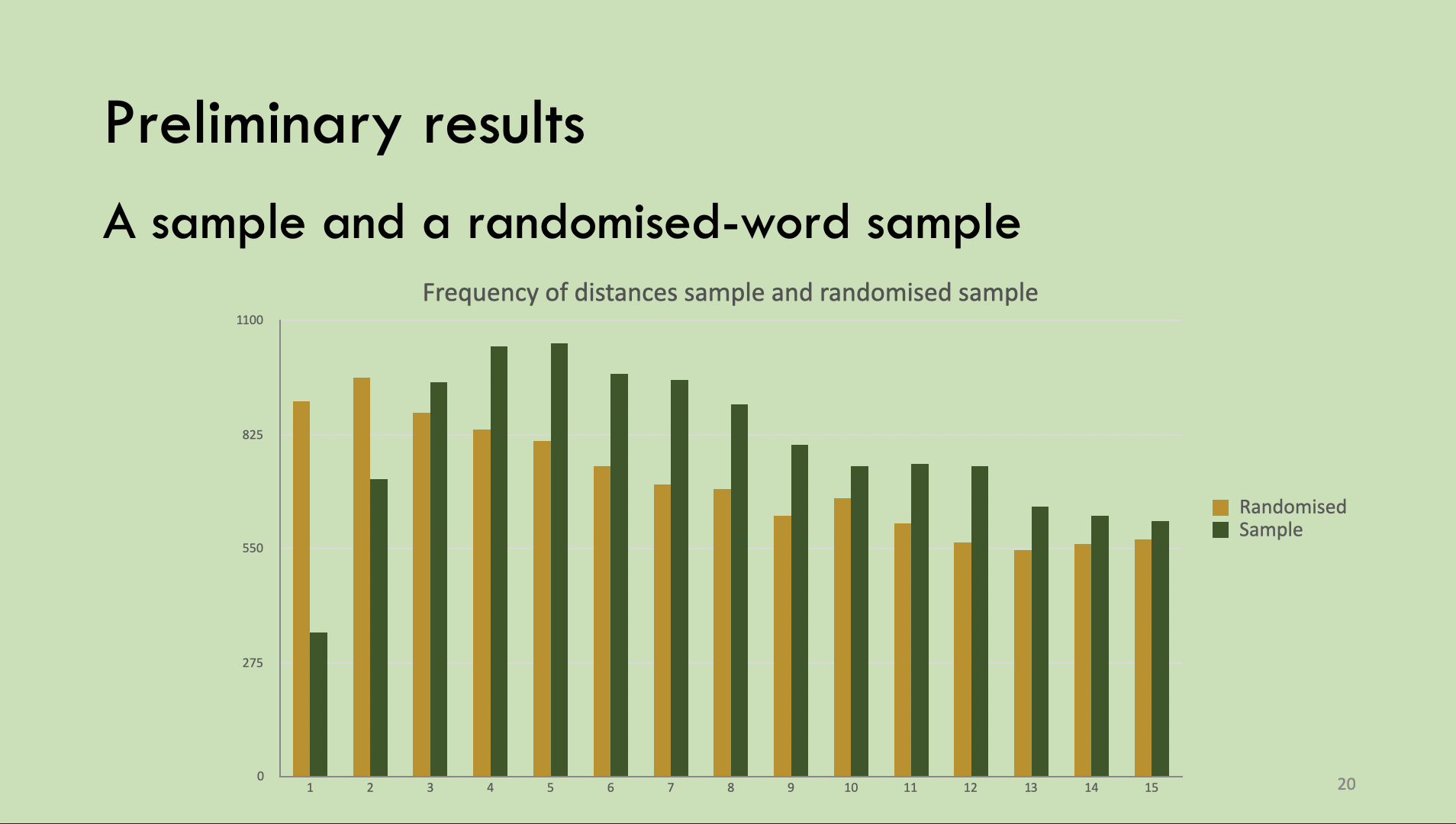
In die romans hebben we voor ieder woord met de computer vastgesteld op welke rijmklank het eindigt en op welke afstand het volgende woord te vinden is dat erop rijmt. Dus als de tekst van de roman luidt: ‘Het kind en de wind zijn bemind.’ Zijn de meegetelde afstanden 3 (tussen kind en wind) en 2 (tussen wind en bemind). Zo hebben we alle afstanden tussen alle rijmende woorden in alle 1100 romans vastgesteld. Dat leverde voor ieder van die romans grafieken op zoals de donkergroene balken hierboven: de afstand 1 (de rijmende woorden staan onmiddellijk naast elkaar) komt ongeveer 300 keer voor, de afstand 2 (er staat één woord tussen) ongeveer 700 keer, en zo voort. Alle grafieken vormen heuveltjes: eerst stijgt het aantal keren dat een afstand voorkomt, en vanaf 6 neemt dat aantal keren gestaag af. In de grafiek hierboven breekt het af bij 15, maar er komen veel langere afstanden voor.
Rijmklanken
Die stijging aan de linkerkant van de heuvel interpreteren wij als het vermijden van rijm. Om dat te laten zien hebben we van elke roman ook een hutspot gemaakt, een ‘gerandomiseerde versie’, waarin de woorden op een door het lot bepaalde willekeurige volgorde worden gezet. Die gerandomiseerde versies hebben nooit zo’n heuveltje aan het begin, ze zakken vanaf afstand 1 meteen. (In het bovenstaande voorbeeld, waarin de bruine balken de scores geven voor de gerandomiseerde versie van dezelfde roman als de donkergroene balken, is afstand 2 wel iets hoger, maar dat valt toe te schrijven aan toeval. Als je aardappelpuree maakt, klontert er weleens wat, maar als je 1100 porties aardappelpuree maakt, kijk je niet meer op een klontertje meer of minder.)
Waarom gaan die grafieken naar beneden? Dat is betrekkelijk gemakkelijk te begrijpen, als je nadenkt over het einde van de grafieken. Daar komen dus woorden voor die op elkaar rijmen maar op enkele tienduizenden woorden afstand van elkaar staan. Dat zijn dus rijmwoorden die niet zo frequent zijn, en omdat ze niet zo frequent zijn, worden ze ook niet meegeteld. Hoogfrequente rijmklanken hebben daarentegen over het algemeen een kortere afstand, eenvoudig omdat er per definitie meer van die hoogfrequente rijmklanken in een tekst staan.
Gegeven dat feit is het feit dat de eerste paar woorden de grafiek consequent stijgt, extra opmerkelijk, en dus, volgens ons, te verklaren door het vermijden van rijm. Waarom is het venster maar zo klein? Dat is nog een open vraag. Het is denkbaar dat op grotere afstanden rijmwoorden ook nog wel vermeden worden, maar dan vooral als ze bijvoorbeeld allebei een zinsaccent hebben – en dat kunnen we in de romans niet zo gemakkelijk zien.
Bewust rijm vermijden. Wie daar erg goed in is, is Roel C. Verburg. Luister maar eens naar zijn ‘slechtste rapper van de straat’ op Youtube.