Dagboek van een amateurprogrammeur
Ook de afgelopen dagen had ik weer veel pret met de verzameling ‘streekromans’ die Ewoud Sanders tijdens de coronadagen ter beschikking stelt. Ik ontdekte dat (voor)namen hoogfrequent zijn in deze boeken en daarna maakte ik een top-3720 van deze voornamen: Jan, Dirk en Kees blijken dominant te zijn en sowieso staan mannennamen hoog in de top. (Dat laatste, bedacht ik later, is mogelijk vooral een teken van het feit dat mensen en ook schrijvers minder fantasievol zijn in het bedenken van mannennamen.)
Ik wilde nu eens onderzoeken of er ontwikkelingen zijn te bespeuren in de tijd. Komen sommige namen op en verdwijnen ze weer? En heeft dat iets te maken met de populariteit van die namen in de wereld buiten de romans? De verzameling van Sanders beslaat ruim een eeuw, van eind negentiende eeuw tot begin eenentwintigste, al is er een duidelijke nadruk op de jaren 1970-1995. De volgende grafiek geeft weer hoeveel woorden er uit ieder jaar in de verzameling terecht zijn gekomen:

Die enorme nadruk op een kleine periode maakt het project om een ontwikkeling in de tijd te volgen eigenlijk al heel lastig. Bovendien doet zich natuurlijk het probleem voor dat een naam ofwel voorkomt in een boek, en dan vaak meteen een heleboel keer ofwel helemaal niet genoemd wordt (boeken met honderden bijfiguren met allemaal een voornaam zijn heel zeldzaam).
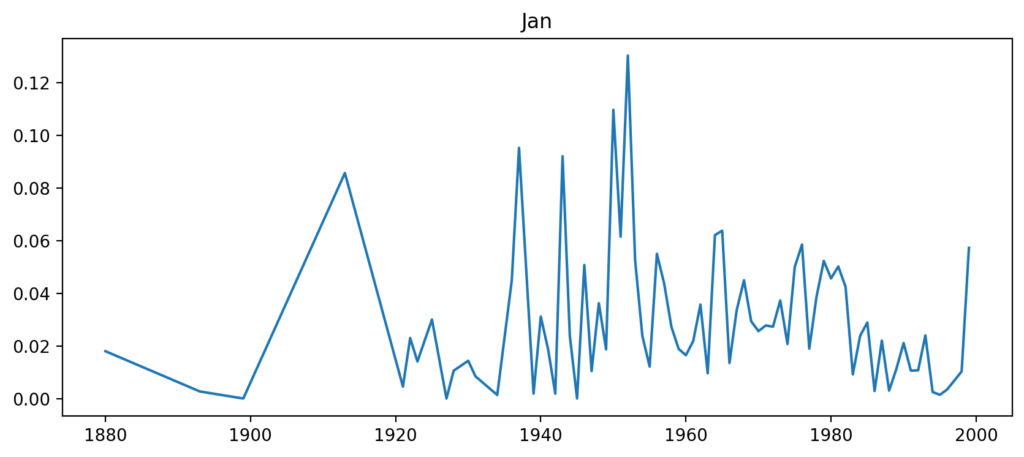
Wanneer je dus de relatieve hoeveelheid voorkomens van individuele namen (hoe vaak komt die naam voor? gedeeld door: hoeveel namen worden er in totaal genoemd in de boeken van een bepaald jaar?) uitzet op een grafiek, krijg je figuren als die bovenaan dit stukje voor de topnaam Jan, en die hieronder voor de veel minder populaire Jane):

Jane speelt een heel belangrijke rol in een roman uit de jaren veertig (haar naam beslaat een derde van alle genoemde namen, dus ze is waarschijnlijk een hoofdpersoon) en daarna wordt ze nog een heel enkele keer genoemd. Jan komt en gaat, meer valt er over die naam op basis van dit plaatje niet te zeggen. En alle grafieken zien er feitelijk zo uit als deze.
Huisnaamkundige van Neerlandistiek Gerrit Bloothooft kwam met de zinnige suggestie om namen te groeperen. Hij heeft daarvoor een classificatiesysteem bedacht dat onder andere gebaseerd is op de herkomst van namen (‘Traditional’, ‘English’, ‘Turkish’), maar waarvan hij in zijn eigen werk heeft laten zien dat het ook in grote lijnen de sociaal-economische herkomst van de naamgevers (de ouders) weerspiegelt. Dus deed ik de exercitie nog eens over, maar nu voor deze groepen.
Je ziet dan wel degelijk voor een paar naamtypes een patroon, zij het tamelijk voorspelbaar én niet heel erg sterk: de traditionele namen nemen na 1940 af, de modernere worden populairder:



Aan deze grafieken valt ook af te lezen dat deze drie naamgroepen samen het leeuwendeel van het namenbestand uitmaken (100%=1.0), in ieder geval in de periode van 1940-2000. Namen uit buitenlandse categorieën zijn te verwaarlozen, hier zijn twee groepen. Voor het Engels zien we onze roman met Jane weer terug, en verder is er een heel lichte gang omhoog:

De categorie Turkse namen laat ook alleen maar zien dat er soms iemand met een Turkse naam voorkomt in een boek; meer valt er geloof ik niet over te zeggen:

Het zelfde geldt voor alle andere typen: ze komen weleens voor, maar alleen omdat er kennelijk onder die duizend boeken altijd wel een paar zitten waarin een personage met zo’n naam zit. (De Turkse namen zijn een paar promille van de namen die genoemd, worden – het gaat dus altijd om personages die één of twee keer worden genoemd.)
Het lijkt dat er subgenres zijn die in de namen gefrelecteerd worden. Namelijk streek-streek met bewust iets ouderwetse echt Nederlandse standaardnamen en meer realistische, moderne streekromans (Yvonne keert terug na haar scheiding terug naar Coevorden) met modenamen (mogelijk ook iets terug in de tijd gekozen: de Scandinavische trend van een paar decennia geleden komt terug met Ingrid, Ingeborg, Astrid, etc., evenals de nog oudere Engelse trend). Het aantal bijbelse namen lijkt beperkt, terwijl die namen toch populair zijn in de Biblebelt. Is reli-streek meegenomen?
De typeringen van de namen is regelmatig niet juist. Komt dat door automatisering? ‘Mieke’ is bijv. gemarkeerd als ‘modern’, ‘Ingrid’ als Dutch-premodern (komt lijkt het duidelijk op met Ingrid Bergman), ‘Leo’ als Dutch-modern (heeft vlgs Voornamenbank piek rond 1945) en Christopher en Matthew als Hebrew.
Gerrit kan er vast meer over zeggen, maar de classificatie is gedaan op basis van sociaal-economische criteria. De ‘etymologische’ labels van die categorieën is daardoor misleidend en lijkt dus niet altijd juist.