Voornamendrift (28)
Door Gerrit Bloothooft
Hoe wordt een nieuw bedacht woord verspreid? Meestal niet via advertenties in de media maar via mond-tot-mond- of schrift-tot-schriftreclame. Je hoort of ziet een neologisme, het bevalt je en je gaat het zelf ook gebruiken. Maar hoe de verspreiding precies in zijn werk gaat is voor taal lastig vast te stellen. Je kunt woorden gaan tellen in geschreven teksten, gaan zoeken wanneer een woord voor het eerst is gebruikt, en de toename en het eventuele verdwijnen in de tijd vaststellen. Heel nauwkeurig is dat allemaal niet. Behalve dan voor voornamen, want daarvan weten we exact wanneer ze aan kinderen zijn gegeven. Daarom zijn sociale wetenschappers die in modeverschijnselen geïnteresseerd blij met de grote voornaambestanden die vooral in Amerika, Frankrijk en Nederland voor onderzoek beschikbaar zijn. Ik heb in deze serie laten zien dat een (sociaal) netwerkmodel heel adequaat is om de verspreiding van namen te beschrijven. Elke naamgeving heeft daarin een kans op een of meer imitaties (door mond op mond reclame), die op hun beurt weer tot nieuwe imitaties leiden, enzovoort. Uiteindelijk zijn er voor de meest populaire voornaam dan 19 imitatiestappen van de eerste tot de laatste naamgeving nodig om meer dan 30.000 naamdragers te bereiken. De essentie van het model is dat de imitatiekans per naam exponentieel afneemt in de tijd (wat ook experimenteel aangetoond is). Maar er zijn ook andere verspreidingsmodellen, die gebaseerd zijn op biologische of economische groei.
De aanname in die modellen is dat groei in eerste instantie exponentieel verloopt en het aantal organismen of producten elk jaar (of tijdseenheid) met een vaste factor toeneemt. Er mag geen externe beïnvloeding van het proces zijn. Maar er is wel een plafond dat bijvoorbeeld wordt bepaald door de beschikbare hoeveelheid voedsel of het maximale aantal geïnteresseerden in een product. Na verloop van tijd remt dat de groei af en wordt het maximaal aantal mogelijke organismen of verkochte producten bereikt. Dat proces kun je op twee manieren bekijken: het aantal organismen of producten dat er per jaar bijkomt, of het totaal aantal organismen of producten na een bepaalde tijd (cumulatief). Daarbij wordt er in eerste instantie van uitgegaan dat er geen organismen dood, of producten kapot gaan. Als dat gebeurt dan worden ze in dezelfde mate vervangen door nieuwe organismen of nieuwe producten, zodat het uiteindelijk evenwicht in stand blijft. Het aardige van zo’n (logistisch) model is dat je alleen maar een groeifactor en een maximum aantal hoeft te veronderstellen.
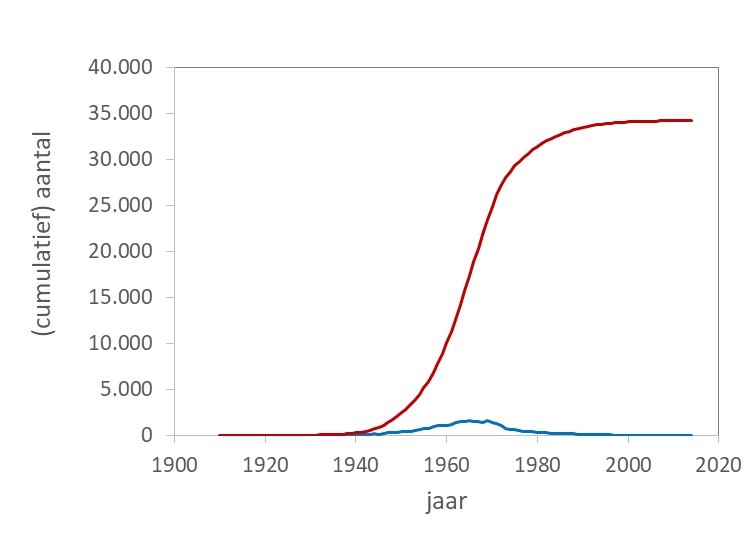
Zo kun je ook tegen de verspreiding van nieuwe voornamen door mond op mond reclame aankijken. De belangstelling voor een nieuwe naam groeit exponentieel, maar het totaal aantal ouders dat er voor kiest is eindig. Figuur 1 laat zowel het aantal kinderen dat de naam Ingrid jaarlijks kreeg, als het totaal aantal kinderen dat de naam tot dat jaar heeft gekregen zien. Waar de jaarlijkse populariteit nog wat fluctuaties laat zien, vallen die bij de cumulatieve verdeling vrijwel weg, het is een bijna perfecte S(igmoid)-curve.
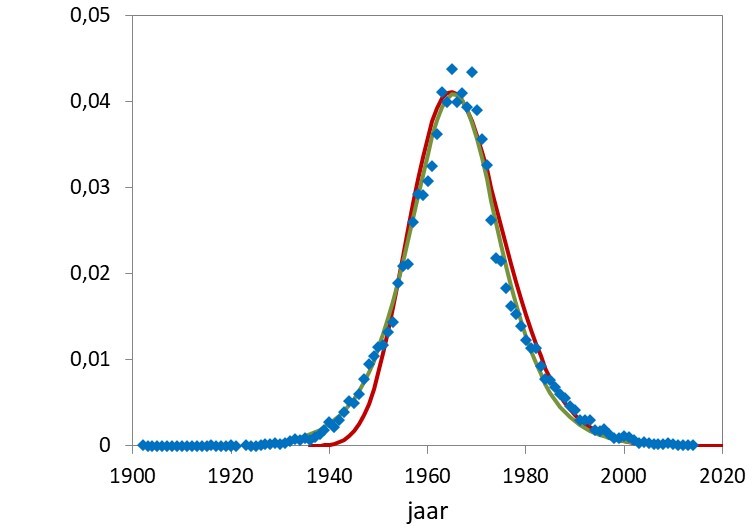
De modellering van de populariteit van Ingrid staat in figuur 2 voor zowel de logistische benadering (groen) als mijn netwerkmodel (rood). Beide modellen kunnen de verdeling prima beschrijven, het logistisch model zelfs iets beter in de beginjaren. De groeifactor in het logistische model is 0,163 wat betekent dat in de eerste jaren elk jaar 16,3% meer meisjes de naam kreeg. Voor het netwerkmodel is de imitatiefactor v=0,35 wat betekent dat er 35% kans is dat een naamgeving binnen een jaar wordt overgenomen door andere ouders, waarna die kans elk jaar met een factor 0,65 (=1-v) kleiner wordt.
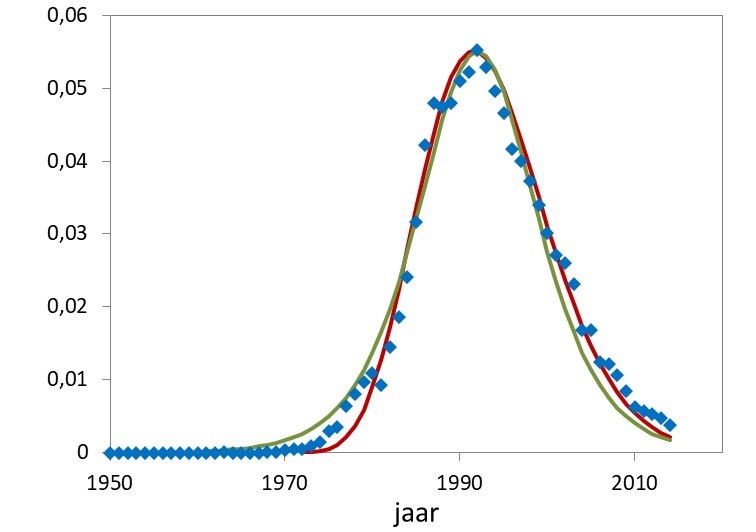
Het is lastig om de twee modellen wiskundig met elkaar in verband te brengen. Ze hebben wel een gelijke eenvoud: ze hangen beiden af van het uiteindelijk aantal naamdragers en hebben beiden een factor die de groei/imitatie beschrijft, zij het op een verschillende manier. Daarnaast is de logistische verdeling strikt symmetrisch, een naam wint en verliest in dezelfde mate aan populariteit. Het netwerkmodel is een beetje scheef, de toename gaat iets sneller dan de afname. Die asymmetrie is bij Ingrid enigszins waar te nemen, maar duidelijker bij Kevin in figuur 3.
Voor beide, zo niet alle modellen, is bij voornamen de vraag wat de beperkende factor is voor het totaal aantal naamdragers. Steeds nieuwe ouders zouden de naam kunnen kiezen, maar dat doen ze niet. Je zou in het logistisch model kunnen denken aan verzadiging: er zijn al zoveel jongens die Sem heten dat nieuwe ouders er van afzien. Maar dat is erg betrekkelijk, de meest populaire naam wordt aan minder dan 1% van de jongens of meisjes gegeven, dus op een basisschool met 600 leerlingen lopen gemiddeld niet meer dan 3 jongens Sem rond. En voor de meeste namen zijn dat er nog veel minder. Behalve dan als de basisschool niet representatief is voor de samenstelling van de bevolking, maar sociaal gekleurd. Omdat sociale groepen hun eigen voorkeuren hebben kan dat binnen zo’n groep (of school) wel eens tot oververtegenwoordiging leiden.
Modenamen beginnen als nieuwe namen. Dat proces van vernieuwing gaat steeds maar door, tegenwoordig krijgt 3% van de jongens en 4% van de meisjes een voornaam die nooit eerder is gegeven. Omdat het totaal aantal geboorten per jaar constant is, is er steeds minder ruimte voor al bestaande namen. Continue vernieuwing creëert zo automatisch een plafond aan het voortbestaan van het oude. En na verloop van tijd zal een volgende generatie weer uit helemaal nieuwe modenamen kiezen.
Maar ook bij een competitie met nieuwe voornamen, hoeven bestaande namen niet helemaal uit de gratie te raken. En toch gebeurt dat. Blijkbaar is er iets intrinsiek aan een naam – misschien iets simpels omdat een naam al lang bestaat en gaandeweg ouderwets gevonden wordt – waardoor de aantrekkelijkheid in de loop van de tijd afneemt tot nul. In het netwerkmodel ligt dat vast doordat de kans dat andere ouders een naam overnemen exponentieel daalt met de tijd. Maar ook in dat model zou een extra stap in het sociale netwerk extra naamgevingen mogelijk maken, wat na een bepaalde tijd niet meer gebeurt, de koek is op.
- De cumulatieve logistische verdeling is N(j-jmax) = K / (1+ e -r(j-jmax)) met r de groeifactor, K het uiteindelijk aantal naamdragers (carrying capacity), en jmax het jaar waarin de toename maximaal is. De afgeleide is de populariteitsverdeling n(j-jmax) = K e -r(j-jmax) / (1+ e -r(j-jmax))2.
- Het logistisch model is door Coulmont et al toegepast op Amerikaanse, Franse en Nederlandse voornamen.
- De populariteitsverdeling van Ingrid in figuur 2 is relatief zowel ten opzichte van het totaal aantal geboorten per jaar als het totaal aantal meisjes (34.262) dat de naam kreeg.
- Voor Kevin (totaal aantal jongens is 23.162) is de logistische groeifactor r= 0,22 en de netwerk imitatiefactor v=0,43. Dwz de groei is sneller dan voor Ingrid met r=0,163 en v=0,35.
Mond op mond reclame? Beetje intiem lijkt mij! Ik geef over het algemeen de voorkeur aan mond tot mond. De juiste spelling is trouwens mond-tot-mondreclame.
Zeer interessant weer, dank.
Je schreef: ‘Je zou in het logistisch model kunnen denken aan verzadiging: er zijn al zoveel jongens die Sem heten dat nieuwe ouders er van afzien. Maar dat is erg betrekkelijk, de meest populaire naam wordt aan minder dan 1% van de jongens of meisjes gegeven, dus op een basisschool met 600 leerlingen lopen gemiddeld niet meer dan 3 jongens Sem rond. ‘
Moet je hier niet ook rekening houden met andere namen? De kans dat er een willekeurige naam op een school vertegenwoordigd is (Sem, Anna, Tom, Emma, Dylan, etc.) is al een stuk groter. En dan zijn er nog namen die je hoort via de bladen, van de gym/judo, van kinderen van collega’s, bekende Nederlanders, etc, plus het rijtje populaire namen dat de SVB publiceert. Misschien tellen ook nog de stijlaspecten mee. Eenlettergrepige namen zijn bijvoorbeeld populair. Dat geeft mogelijk een tegentrend van ouders die al dan niet bewust juist voor meerlettergrepig kiezen (de Alexanders, Sebastiaans en Esmeralda’s). Ook het einde van de namen telt misschien nog mee, bijvoorbeeld namen op -o, -an, -m. En de herkomst, bijvoorbeeld Amerikaans, Bijbels, Fries, Brits, etc. De hierboven genoemde Ingrid past denk ik in een trend van Scandinavische namen met Astrid, Ingeborg, Holger, Olaf, Nils, etc. Ook dat geeft verzadiging misschien, voor zover ouders daar een radar voor hebben.