(Persbericht Radboud Universiteit)
Wist je dat in iedere taal het meest voorkomende woord ongeveer twee keer zo vaak voorkomt als het op een na meest voorkomende woord? Deze wet genaamd ‘Zipf’s law’ is al ruim een eeuw oud, maar tot nu toe lukte het wetenschappers niet om het verschijnsel precies te verklaren. Taalwetenschapper Sander Lestrade van de Radboud Universiteit publiceerde een oplossing voor dit notoire probleem in het wetenschappelijk tijdschrift PLOS ONE.
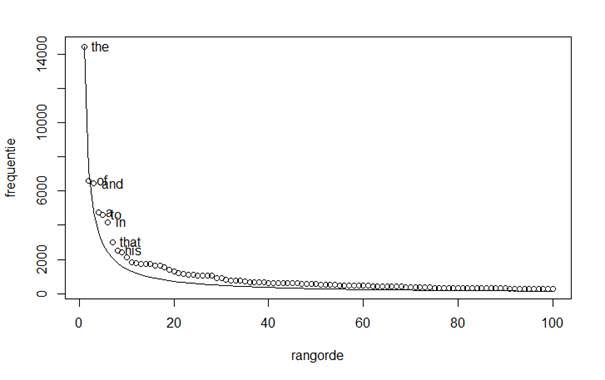
Zipf’s law beschrijft hoe de frequentie van een woord in natuurlijke taal afhankelijk is van zijn rangorde in een frequentietelling. Het meeste voorkomende woord komt twee keer zo vaak voor als het op een na meest voorkomende woord, drie keer zo vaak als het woord daarna, en zo door tot aan het minst voorkomende woord (zie Figuur 1). De wetmatigheid is vernoemd naar de Amerikaanse linguïst George Kingsley Zipf die deze rond 1935 als eerste probeerde te verklaren.
Grootste raadsel van de computationele taalkunde
‘Ik denk dat je best kunt stellen dat Zipf’s law het grootste raadsel van de computationele taalkunde is’, aldus Sander Lestrade, taalwetenschapper aan de Radboud Universiteit. ‘Tot nu toe is de wet nooit fatsoenlijk taalkundig onderbouwd.’ Lestrade toont nu aan dat Zipf’s law te verklaren is door de interactie tussen de zinsbouw en regels (syntaxis) en de betekenis van woorden (semantiek) in een tekst. Met behulp van computersimulaties toont de onderzoeker aan dat syntaxis of semantiek op zichzelf geen Zipfiaanse distributie in een tekst tot stand kunnen brengen, maar dat ze elkaar daarvoor ‘nodig hebben.
‘In de Nederlandse taal, en trouwens ook in de Engelse, zijn er bijvoorbeeld slechts drie lidwoorden, maar tienduizenden zelfstandige naamwoorden’, legt Lestrade uit. ‘Je gebruikt voor bijna ieder zelfstandig naamwoord een lidwoord, en dus komen lidwoorden gemiddeld veel vaker voor dan zelfstandige naamwoorden.’ Maar dat is niet voldoende om Zipf’s law te verklaren. ‘Binnen de zelfstandige naamwoorden heb je ook weer grote verschillen. “Ding” is bijvoorbeeld veel algemener dan “onderzeeboot”, en kan dus in principe vaker gebruikt worden. Maar om daadwerkelijk frequent voor te komen, moet een woord ook weer niet te algemeen zijn. Als je de betekenisverschillen binnen woordklassen “vermenigvuldigt” met de behoefte aan iedere klasse, krijg je een schitterende Zipfiaanse verdeling, die precies zo afwijkt van het Zipfiaanse ideaal als natuurlijke taal doet. Want Zipf’s law klopt eigenlijk net niet helemaal, zoals je kunt zien in Figuur 1.’
Voorspellingen op basis van Lestrades nieuwe model blijken volledig overeen te komen met verschijnselen in natuurlijke taal. ‘En mijn theorie geldt voor grofweg alle talen, dus niet alleen voor het Nederlands of het Engels’, stelt hij. ‘Ik vind deze vondst echt heel leuk, en ben overtuigd van mijn oplossing. Maar, de bevestiging moet natuurlijk van andere taalkundigen komen.’
Publicatie:
Wat zijn in het Nederlands de meest voorkomende woorden in volgorde van voorkomen?
Ik heb een veel simpelere oplossing voor dit taalraadsel: 42.
Humoristen als Charles Lamb, William Clarke, S.J. Perelman vervingen soms een eenvoudig woord door een volkomen obscuur exemplaar. Misschien om de lezer die het moest opzoeken het prettige gevoel te geven dat die nu een stuk dichter bij de beschaving stond, je weet het niet.
De woordplot van elk verhaal zou er natuurlijk hetzelfde uitzien als het eenvoudige woord was gebruikt.
De woordfrequentietelling — want meer is het niet — in de zin van Zipf is de som van denkbare uitingen. Een plot zoals de bovenstaande draagt daar 1/zeerveel aan bij. Ik zou het wel supermooi vinden als de som van syntactische en semantische mogelijkheden zo gelijk loopt aan de som der bedachte taaluitingen als hier wordt gesteld.
Andere toepassingen kunnen wel aardig laten zien dat een frequent gebruikt naamwoord als ‘racisme’ (topicalisatie) ten koste gaat van de variatie in argumentatie (van Anne Fleur Dekker).
Of, op hoger niveau, zou je er leuke dingen mee kunnen vinden in De Metsiers of in Stijloefeningen.
even een copy/paste van mijn reacties opTwitter(die toch niemand leest):
Ik snap het probleem niet zo. Uiteindelijk is de bijdrage van een woord aan de totale entropie dus de som van de bijdrage van het naakte woord en die van zijn klasse(n).
En het verschil met de “power-law” distributie komt doordat je met woordfrequentie in feite het verkeerde meet. Waarschijnlijk kom je met toevoeging van(de frequenties van) uitsluitend N-grammen ook al dichter bij de voorspelde verdeling.(N-gram als benadering vd bijdrage van syntaxis/klasse van het woord)
Nou, N-grammen uit de grammatica gaan een heleboel overlappingen opleveren die met zijn allen opgeteld mijlenver afliggen van de verdeling van woordfrequenties in allerlei geturfde verhalen. Zipf op te vatten als gemiddelde van dat totaal.
Ik gebruik optellen, omdat ik in entropie reken. Dat gaat logaritmisch. Dat optellen is dus hetzelfde als de vermenigvuldiging met de “behoefte” van de woordklasse in het artikel hierboven.
Trouwens: Zipf’s law is niet alleen “naar boven”uit te breiden, maar ook “naar onderen”: ruim voor Zipf turfde Samuel Morse de letterfrequenties van een (engelstalige) krantenpagina, om zo een efficienter morse-alfabet te kunnen definieren. (e en t hebben bijv de kortste Morse-code)