Een vrij waarschijnlijk universeel kenmerk van talen is dat ze woorden hebben: de stroom geluiden die uit iemands mond komt, kan worden opgehakt in kleinere stukjes die een vrij duidelijke betekenis hebben en met die betekenis vaker voorkomen in andere stromen geluiden. De grootte van woorden kan verschillen – in onze taal zijn heel veel woorden eenlettergrepig, behalve … [Lees meer...] overWoorden zijn cultuur
Wet van Zipf
Afasie en de vorm van het menselijk geheugen

Door Marc van Oostendorp Sommige dingen hebben alle talen met elkaar gemeen terwijl eigenlijk niemand weet waarom. Het geldt onder andere voor de Wet van Zipf. Zodra je een verzameling taalmateriaal neemt van voldoende omvang, gaat dit aan deze statistische wet voldoen. Gerrit Bloothooft schreef bijvoorbeeld eerder dit jaar uitgebreid over het feit dat hij ook geldt … [Lees meer...] overAfasie en de vorm van het menselijk geheugen
Zipf plus Zipf blijft Zipf
Voornamendrift (4) Door Gerrit Bloothooft Onze voornamen zijn een mengelmoes. Er zijn traditionele voornamen van christelijke of germaanse oorsprong, er wordt geleend van omringende talen in Europa, en door migratie kunnen we voornamen uit de hele wereld tegenkomen. En toch vinden we alles bij elkaar voor de hele bevolking een aantal voornamen met een bepaalde frequentie dat … [Lees meer...] overZipf plus Zipf blijft Zipf
De wet van Zipf
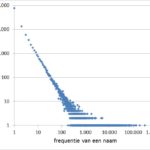
Voornamendrift (3) Door Gerrit Bloothooft Er zijn populaire voornamen en er zijn zeldzame en unieke voornamen, en alles daar tussenin. Met een voornaam bedoel ik hier de eerste, officiële voornaam, en niet de roepnaam want die wordt in de bevolkingsadministratie niet geregistreerd. Voor elke voornaam weten we het aantal naamdragers en we kunnen bijvoorbeeld tellen hoeveel … [Lees meer...] overDe wet van Zipf
Voornamendrift: de aftrap
Voornamendrift (1) Door Gerrit Bloothooft We hebben allemaal een voornaam die door onze ouders is gekozen. Ik ga in een serie bijdragen op zoek naar de vrijheid die ouders daarbij hebben. Vanuit de sociologie wordt wel beweerd dat de voornaamkeuze bijzonder is omdat die niet onderhevig is aan externe, commerciële invloeden. Daarom kan de voornaamkeuze een directe reflectie … [Lees meer...] overVoornamendrift: de aftrap
Oplossing voor taalkundig probleem van 100 jaar oud

(Persbericht Radboud Universiteit) Wist je dat in iedere taal het meest voorkomende woord ongeveer twee keer zo vaak voorkomt als het op een na meest voorkomende woord? Deze wet genaamd ‘Zipf’s law’ is al ruim een eeuw oud, maar tot nu toe lukte het wetenschappers niet om het verschijnsel precies te verklaren. Taalwetenschapper Sander Lestrade van de Radboud Universiteit … [Lees meer...] overOplossing voor taalkundig probleem van 100 jaar oud
Hitler hield niet van joodse kunstenaars
We weten niet wat we met al die gegevens aanmoeten Door Marc van Oostendorp We beschikken over een schat aan informatie, een gigantische schat, een dankzij het internet almaar groter wordende schat. En we hebben geen idee wat we in hemelsnaam met die schat moeten doen. Dat is de indruk die je krijgt van het boek Uncharted. Big Data as a Lens on Human Culture van Erez Aiden en … [Lees meer...] overHitler hield niet van joodse kunstenaars
Mandelbrot de taalkundige
Door Marc van Oostendorp De grote wiskundige Benoit B. Mandelbrot – onder meer de ontdekker van de fractals – had eigenlijk taalkundige willen worden, maar hij werd tegengehouden door Noam Chomsky. Dat kwam zo. In de jaren vijftig kwam Mandelbrot naar het Massachusetts Institute of Technology (MIT) nadat hij net statistisch werk had gedaan over taal. "Daar kwam ik vervolgens … [Lees meer...] overMandelbrot de taalkundige
Geschiedenis van de woordfrequentie
Frequentie is in de taalwetenschap al een tijdje een toverwoord. Woorden die vaak voorkomen, die hoogfrequent zijn, zijn bijzonder. Ze zijn bijvoorbeeld gemiddeld korter dan laagfrequente woorden volgens een van de bekendste wetten van de taalwetenschap, de Wet van Zipf. Ook spreken sprekers dit soort woorden vaak wat achtelozer uit: omdat ze zo vaak voorkomen, voegen ze minder … [Lees meer...] overGeschiedenis van de woordfrequentie