
Ik heb in Neerlandistiek wel eens iets van mijn verbazing laten merken over het feit dat een niet gering deel van de literatuurwetenschap, de zusterdiscipline van mijn eigen vak (taalkunde), een enorme interesse heeft ontwikkeld voor genderkwesties. Ik heb dat toen een “obsessie” genoemd, en in een adem gezegd dat ik me stoorde aan de moraliserende toon. Dat klonk onaardig. En … [Lees meer...] overHand in eigen boezem: de obsessie van de variatietaalkunde
statistiek
Dialecten meten
Door Marc van Oostendorp Martijn Wieling (Rijksuniversiteit Groningen) doet onderzoek naar dialectvariatie met behulp van statistiek. Hoe is hij daartoe gekomen? En wat is er de lol van? "Heel veel gegevens liggen gratis voor het opscheppen, waar we nog niet het begin van een patroon in hebben ontdekt." Bekijk deze video op YouTube De website van Martijn Wieling … [Lees meer...] overDialecten meten
2000 twijfelachtige stukjes

Door Marc van Oostendorp Omdat ik deze week mijn 2000e stukje op Neerlandistiek heb geplaatst, heb ik eens door wat oudere blogs gebladerd. Sommige was ik vergeten en die zijn natuurlijk altijd het leukst, want mijn posts gaan onveranderlijk over onderwerpen die mij interesseren. Ik schreef precies vijf jaar geleden bijvoorbeeld over de vraag hoe reëel een kans is … [Lees meer...] over2000 twijfelachtige stukjes
Het nut van statistiek
Door Marc van Oostendorp Van verschillende kanten kreeg ik dit artikel aangeraden van de beroemde statisticus en blogger Andrew Gelman en een Australische biostatisticus John Carlin. Het artikel is deels een reactie op een artikel van nog weer andere statistici, Blakeley McShane en David Gal: never a dull moment in de wereld van de multiple regressie! Er is in sommige … [Lees meer...] overHet nut van statistiek
Sanskriet op de beat
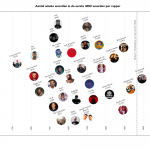
De grootste woordenschat in nederhop Door Alex Reuneker (Universiteit Leiden), Vivien Waszink (Instituut voor de Nederlandse Taal) en Ton van der Wouden (Meertens Instituut) Op The Pudding - een onlinetijdschrift met ‘visuele essays’ - verscheen een interessant onderzoekje naar de woordenschat van Amerikaanse hiphopartiesten. De vraag was simpel: ‘Als literatuurliefhebbers … [Lees meer...] overSanskriet op de beat
Het geluid van een Bayesiaanse machine

Door Marc van Oostendorp Het fijnste van onderzoeker zijn is dat je af en toe overtuigd raakt: eerst wist je zeker dat het zus zat, en dan merk je ineens dat je begrijpt dat het toch echt zo is. Vooral de onderzoeker op rijpere leeftijd, zoals ik, kan dat af en toe overkomen. In eerste instantie zag ik bijvoorbeeld weinig in het nieuwe artikel The Message Shapes Phonology, … [Lees meer...] overHet geluid van een Bayesiaanse machine
Een lesje kansberekening
Door Marc van OostendorpToen ik me ruim een jaar geleden hier op Neder-L afvroeg of studenten in het wetenschappelijk onderwijs wel echt gemiddeld veertig fouten per A4'tje maakten, en hbo'ers tachtig, wist ik niet wat ik me op de hals haalde.Het werd een lange tocht om te proberen de teksten te achterhalen waar al die fouten dan in zouden staan; een tocht die zelfs langs … [Lees meer...] overEen lesje kansberekening
Onderzoek bewijst: taaldiversiteit zorgt voor verkeersongelukken
Door Marc van OostendorpHoe meer talen er in een land gesproken worden, des te groter is de kans op verkeersongelukken. In landen waar acacia's groeien, wordt veel vaker gebruik gemaakt van toonhoogte om betekenisverschil te maken tussen woorden. En hoe meer siësta's de mensen houden, des te minder naamvallen, vervoegingen en verbuigingen gebruiken ze in hun taal.Het zijn … [Lees meer...] overOnderzoek bewijst: taaldiversiteit zorgt voor verkeersongelukken
72.095 woorden
Hoeveel praten Kamerleden? Door Marc van Oostendorp Wanneer het Kamerlid Ybeltje Berckmoes-Duindam dit jaar tien keer haar naam had uitgesproken tijdens een plenaire vergadering, had ze evenveel gezegd als ze nu volgens Vrij Nederland heeft gedaan: 32 woorden. Ze had ook alleen de vorige zin kunnen uitspreken. Volgens Vrij Nederland is de VVD'ster de 'backbencher' van … [Lees meer...] over72.095 woorden