
Wat is literatuur? Is literaire kwaliteit meetbaar? Karina van Dalen-Oskam vroeg duizenden lezers welke romans ze recent hadden gelezen, wat ze ervan vonden, hoe ze oordeelden over de kwaliteit en waar ze hun oordeel op baseerden. Deze oordelen worden vergeleken met de resultaten van een doormeting van 401 moderne Nederlandse en vertaalde romans met behulp van … [Lees meer...] overBinnenkort verschijnt: Het raadsel literatuur
e-humanities
Een teken van literaire kwaliteit
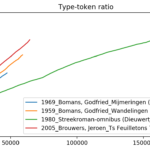
Als een voordeel van boeken lezen wordt wel genoemd dat je er je woordenschat mee uitbreidt, en ook wordt (geloof ik) weleens beweerd dat je beter literaire boeken kunt lezen dan bijvoorbeeld streekromans. Maar klopt dat wel? Dat bestudeerde ik aan de hand van de collectie van 1100 streekromans die Ewoud Sanders onlangs in het kader van de algehele coronasolidariteit in het … [Lees meer...] overEen teken van literaire kwaliteit
Betrouwbare computers en onbetrouwbare romans

Misschien is een van de problemen in de relatie tussen literatuurwetenschap en de computer dat veel letterkundigen niet van saai werk houden – zelfs niet al het door een apparaat wordt gedaan. Maar misschien is het probleem ook dat het werk dat de computer doet echt té saai is om een interessante studie te kunnen opleveren. … [Lees meer...] overBetrouwbare computers en onbetrouwbare romans
30 november 2018, Utrecht: Bijeenkomst over distant reading
Het onderzoeksplatform Datafied Society en Het Utrecht Data Science & Humanities Centre organiseren op 30 november een discussie bijeenkomst over Distant Reading. Aanleiding is de blogpost van Marc van Oostendorp waarin de vruchtbaarheid van de betreffende leeshouding wordt betwijfeld. De professor zal zijn twijfels in persoon komen toelichten, waarna sprekers van het … [Lees meer...] over30 november 2018, Utrecht: Bijeenkomst over distant reading
Liever schone data dan veel data
Door Marten van der Meulen Vorige week schreef ik een blogpost naar aanleiding van een stuk van Marc van Oostendorp (die weer reageerde op een tweet van Geert Wilders). In de post beschreef ik het gebruik van een bepaald woord, difficulteren, aan de hand van een aantal verschillende corpora van het Nederlands. Mijn post bleek op haar beurt aanleiding voor professor Jan Odijk … [Lees meer...] overLiever schone data dan veel data
‘Difficulteren’ zoeken met digitale methoden
Door Jan Odijk Clariah is een groot project dat de empirische basis voor digitaal geesteswetenschappelijk onderzoek wil faciliteren. In de CLARIAH-PLUS-aanvraag (p. 8) wordt gesteld: “The CLARIAH infrastructure will increase our empirical base, options for analysing […] data, and the efficiency of research by orders of magnitude (data-intensive science).” Maar is dat ook echt … [Lees meer...] over‘Difficulteren’ zoeken met digitale methoden
Literaire stijl als een computerkunstje

(Persbericht Radhoud Universiteit) Is de creatie van een uniek literair oeuvre voorbehouden aan zwoegende schrijvers of kan een computer de klassiekers imiteren? In het project ‘Writers in the Cloud’ schrijven bezoekers van het Erasmusgebouw van de universiteit met behulp van taaltechnologie een tekst in de trant van schrijvers als Couperus, Grunberg of Bervoets. Het project … [Lees meer...] overLiteraire stijl als een computerkunstje
Dialect App: Eèsjdes en Mestreechs
Door Leonie Cornips Een wens is eindelijk in vervulling gegaan. Zo’n drie jaar geleden spraken Lukas van der Hijden (Bureau Interactieve Communicatie) en ik met elkaar af hoe we een Dialect App zouden kunnen realiseren, een idee dat al langer leefde bij streektaalfunctionaris Ton van de Wijngaard. Het ontwikkelen van zo’n (web)App door een bureau kost geld, er is technische … [Lees meer...] overDialect App: Eèsjdes en Mestreechs
Vacature Coördinator DARIAH en digital humanities VUB (20-30%)
De Vrije Universiteit Brussel stapt sinds dit jaar mee als partner in het DARIAH-Vlaanderen-project. DARIAH is een internationaal consortium dat gericht is op het verbeteren en ondersteunen van digitaal onderzoek en onderwijs binnen de geesteswetenschappen (zie bijv. http://be.dariah.eu, http://www.dariah.eu of deze presentatie voor meer achtergrond, of zie bijv. ook de … [Lees meer...] overVacature Coördinator DARIAH en digital humanities VUB (20-30%)
Taalkundigen: kom uit bed!
Door Marc van Oostendorp Taalkunde kun je overal doen. In de bus onderweg van de boerderij waar je een mummelende boer hebt gevraagd of de klok even stil kon worden gezet om de opname niet te bederven. In het bezemhok dat op menige universiteit tevens dienst doet als 'taalkundig laboratorium' omdat er een laptop in staat met een koptelefoon. En ook in bed, waar je peinst over … [Lees meer...] overTaalkundigen: kom uit bed!
24 maart 2017: Jaarvergadering ‘Het Bilderdijk-Museum’
INVITATIE voor een middag met lezingen over ‘Bilderdijk digitaal’ en ‘Helmers herdacht’ Vrijdag 24 maart 2017 Vrije Universiteit, De Boelelaan 1105, Amsterdam. Zaal Forum 2 (hoofdingang, 1e verdieping) PROGRAMMA 13.00 inloop 13.30 ledenvergadering 14.00 lezing Joris van Eijnatten: ‘De dichter courant. Bilderdijks digitale afdruk in één miljoen kranten’ 14.45 pauze 15.00 … [Lees meer...] over24 maart 2017: Jaarvergadering ‘Het Bilderdijk-Museum’
Radboud Digital Humanities Spring School 2017
This spring school at Radboud University offers courses into several widely-used techniques and tools in Digital Humanities. It will be held in three consecutive days, 29-31 March 2017, at the Faculty of Arts at Radboud University. The Spring School will be given in two parallel strands. The first strand of will contain a three days fulltime basic Python course. Python is … [Lees meer...] overRadboud Digital Humanities Spring School 2017
450 maal Roodkapje
Door Marc van Oostendorp Onlangs promoveerde Folgert Karsdorp op een proefschrift waarin hij analyseerde hoe volksverhalen zoals sprookjes mondeling worden overgedragen, en hoe die sprookjes daarbij veranderde. Ik sprak in deze video met Folgert over de 450 versies van Roodkapje die er in omloop zijn en waarom het zin heeft die versies met de computer te analyseren. … [Lees meer...] over450 maal Roodkapje
Breid het bewaarbeleid voor tekstueel erfgoed uit!
Door Nicoline van der Sijs De afgelopen tijd heb ik tweemaal ervaren dat het bewaren van tekstueel erfgoed bijzondere zorg vraagt. En dat in het beleid van de overheid lacunes bestaan die door particulier initiatief worden gedicht. Zo bracht ik onlangs een bezoek aan het Medisch Leesmuseum dat prof.dr. Mart van Lieburg op een Urks bedrijventerrein heeft ingericht. Van … [Lees meer...] overBreid het bewaarbeleid voor tekstueel erfgoed uit!
Hoe schrijf je een bestseller?

Door Marc van Oostendorp Gaat de wetenschap alle schrijvers rijk en beroemd maken? De literair redacteur Jodie Archer en de literatuurwetenschapper Matthew Jockers proberen de verwachtingen van hun lezers weliswaar wat te temperen, maar ze doen dat natuurlijk pas nadat ze die lezers eerst hun boek hebben binnengelokt met een titel (The Bestseller Code. Anatomy of the … [Lees meer...] overHoe schrijf je een bestseller?
Call for proposals KB Researcher-in-residence 2017
The Koninklijke Bibliotheek (KB), National Library of the Netherlands is seeking proposals for its Researcher-in-residence program to start in 2017. This program offers a chance to early career researchers to work in the library with the Digital Humanities team and KB data. In return, we learn how researchers use the data of the KB. Together we will address your research … [Lees meer...] overCall for proposals KB Researcher-in-residence 2017
Een man met dezelfde eigenschappen als iedereen
President Tsaar op Obama Beach op de voet gevolgd (5/60) Door Marc van Oostendorp Deze zomer publiceren nrc.next en NRC Handelsblad de roman President Tsaar op Obama Beach van A.F.Th. van der Heijden als feuilleton. De afleveringen verschijnen 's ochtends <op de website van de krant>. In de loop van de dag blog ik een bespreking. Vandaag: aflevering 5. Natan … [Lees meer...] overEen man met dezelfde eigenschappen als iedereen
Nieuwe artikel Journal of Dutch Literature: Mapping the Demographic Landscape of Characters in Recent Dutch Prose
Mapping the Demographic Landscape of Characters in Recent Dutch Prose: A Quantitative Approach to Literary Representation / Het demografisch landschap van literaire personages in de recente Nederlandse roman: een kwantitatieve benadering van literaire representaties Lucas van der Deijl; Saskia Pieterse; Marion Prinse; Roel Smeets Abstract The lack of ethnic and gender … [Lees meer...] overNieuwe artikel Journal of Dutch Literature: Mapping the Demographic Landscape of Characters in Recent Dutch Prose
Waarom taalkundigen kaarten maken
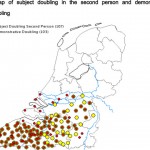
Door Marc van Oostendorp Wij van het Meertens Instituut, wij maken, zoals jullie weten, kaarten. Dat doen we al tientallen jaren tot ieders tevredenheid – vroeger met de hand, en tegenwoordig met de computer. Maar nu opgelet, want hier volgt een goede vraag: waarom maken we eigenlijk die kaarten. Wat moet je ermee, behalve je eigen geboorteplaats opzoeken om te kijken of er … [Lees meer...] overWaarom taalkundigen kaarten maken
Louis Peter Grijp-lezing online
De eerste Louis Peter Grijp-lezing werd op 10 mei 2016 gehouden door Mike Kestemont, en ging over computationale methoden waarmee het auteurschap van het Wilhelmus mogelijk te bepalen is. De Louis Peter Grijp-lezing is een jaarlijks evenement dat wordt georganiseerd ter nagedachtenis van de recent overleden onderzoeker Louis Grijp, die internationale bekendheid verwierf als … [Lees meer...] overLouis Peter Grijp-lezing online
Toevallig op Petrus Datheen stuiten

Door Marc van Oostendorp Wijlen Louis Peter Grijp was begrijpelijkerwijze trots toen er voor zijn dood een nieuw instituut werd ingericht – de Louis Peter Grijp-lezing, jaarlijks te houden rond 10 mei, de verjaardag van het Wilhelmus als Nederlands volkslied. Hij was ook trots op de eerste spreker, de aanstormende Antwerpse literatuurwetenschapper Mike Kestemont. Gisteren … [Lees meer...] overToevallig op Petrus Datheen stuiten
KB-fellow Huub Wijfjes over ontzuiling en de rol van de media
Tot in de jaren zestig van de vorige eeuw was de Nederlandse samenleving sterk verzuild. Protestanten, katholieken, liberalen en socialisten hadden allemaal hun eigen verenigingen, scholen, tijdschriften en kranten. Daarna volgde een hevige periode van ontzuiling, waarin verschillende media een belangrijke rol speelden. Mediahistoricus Huub Wijfjes onderzoekt al jaren de … [Lees meer...] overKB-fellow Huub Wijfjes over ontzuiling en de rol van de media
Oproep: lacunes in datasets voor neerlandistisch onderzoek
Binnen de geesteswetenschappen van de KNAW ontwikkelt een consortium momenteel plannen om een onderzoeksagenda voor de toekomst (2025) te formuleren, getiteld DESIDERIA (Dutch Extensible and Searchable Infrastructure for Digital Explorative Reading and Information Analysis). Die agenda is gericht op onderzoek aan de hand van grote tekstcorpora en sluit aan bij huidige … [Lees meer...] overOproep: lacunes in datasets voor neerlandistisch onderzoek
Oproep: artikelen over Delpher
Voor een themanummer over Delpher (de online toegang tot gedigitaliseerd historisch tekstmateriaal) is TS> Tijdschrift voor Tijdschriftstudies op zoek naar bijdragen vanuit verschillende disciplines (zoals Nederlands, Cultuur- en Kunstgeschiedenis, Mediastudies, Tijdschriftstudies, Communicatiewetenschap en gerelateerde vakgebieden) die (voor een deel) gebaseerd zijn op, … [Lees meer...] overOproep: artikelen over Delpher
Ondergronds
Door Peter van KranenburgVoordracht gehouden op het symposium “Luid zingend op een ijsschots de zomer tegemoet”, ter gelegenheid van de 60ste verjaardag van Nicoline van der Sijs.Waar gaat het heen met de geesteswetenschappen? Dat is een zeer grote vraag waar op velerlei manieren antwoord op te geven is. Ik ga me niet wagen aan voorspellingen, maar ik richt me in deze bijdrage … [Lees meer...] overOndergronds