
Dit nieuwe corpus maakt duizenden 17e-eeuwse kranten goed toegankelijk Wilt u uit de eerste hand weten wat er in het Rampjaar 1672 gebeurde? Bent u benieuwd in welke jaren er wolvenplagen waren? Of zoekt u de oudste advertenties voor een geneesmiddel ‘voor alle Qualen op de Borst, Benaeutheden, Hoest en Sinckingen’? Dan kunt u te rade gaan in … [Lees meer...] overCouranten Corpus staat online
corpus
Corpus Hedendaags Nederlands online
Bij de verschijning van de nieuwe Algemene Nederlandse Spraakkunst ontstond grote beroering over het gebruik van als en dan na een comparatief. Veel mensen klommen in de pen en spraken hun afkeur uit over bijvoorbeeld groter als. Hoewel in verzorgd Nederlands groter dan nog altijd de norm lijkt te zijn, is groter als niet ongebruikelijk. Maar hoe vaak komen beide varianten … [Lees meer...] overCorpus Hedendaags Nederlands online
Nieuwe versie corpus Brieven als Buit online
Door Roland de Bonth (Instituut voor de Nederlandse Taal) Gisteren heeft het Instituut voor de Nederlandse Taal een nieuwe, derde versie van de internetapplicatie Brieven als Buit uitgebracht. Dit corpus bevat 1033 brieven uit de 17e en 18e eeuw die familieleden, vrienden, bekenden en zakenpartners vanuit het buitenland naar hun vaderland hebben gestuurd of – … [Lees meer...] overNieuwe versie corpus Brieven als Buit online
Het NAMES corpus met 850.000 namen, gratis
Voornamendrift 59 Door Gerrit Bloothooft Het CLARIAH project NAMES had tot doel om 189.707 verschillende enkelvoudige voornamen (61,9 miljoen voorkomens) en 562.676 verschillende enkelvoudige achternamen (54,5 miljoen voorkomens) uit de 19e eeuwse burgerlijke stand (wiewaswie.nl versie 2011) zoveel mogelijk te voorzien van een standaardvorm. Dat zijn praktische … [Lees meer...] overHet NAMES corpus met 850.000 namen, gratis
Een corpus van roepnamen en voornamen
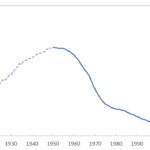
Voornamendrift (34) Door Gerrit Bloothooft en David Onland Niet iedereen heeft een voornaam die ook zo in de burgerlijke stand staat. Dat noemen we dan de roepnaam, terwijl de officiële naam ook wel de doopnaam wordt genoemd. Blijkbaar forceert de kerk in de doop een voornaam die ouders ook aan de staat doorgeven, maar die in de dagelijkse praktijk niet functioneert. ‘Wim, … [Lees meer...] overEen corpus van roepnamen en voornamen