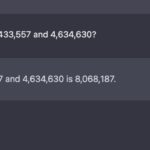
Het menselijk gedruis over tekst producerende kunstmatige intelligentie zal nog wel even voortduren. ChatGPT hielp me begin deze maand een artikel schrijven dat volgens sommigen behoorde tot het beste dat ik ooit schreef. Sindsdien ben ik ermee blijven experimenteren – vaak nog verbaasd over wat het systeem ineens bleek te kunnen bedenken, maar gaandeweg toch ook steeds meer … [Lees meer...] overChatbot kan niet langzaam denken
computertaalkunde
Chattie

Op het Meertens Instituut moesten we vroeger altijd een beetje gniffelen als er weer een bobo van het Hoofdbureau langskwam om ons te vertellen dat de digitalisering ‘revolutionaire nieuwe inzichten’ in ons onderzoek ging bieden (en dat we zo snel mogelijk zoveel mogelijk geld hiervoor binnen moesten zien te slepen). Natuurlijk gebruikten we de computer als hulpmiddel, maar dat … [Lees meer...] overChattie
sChatje, maak eens een tentamenvraag

Wil ik best toegeven, ik was verslaafd, de afgelopen twee weken. En nog, als ik iets vervelends moet doen, zoals kerstkaarten sturen, R-scripts schrijven of abstracts maken, dan is mijn eerste neiging: kan ChatGPT dat niet doen? sChatje, kun jij voor mij een kerstkaart naar Tante Annie sturen? Inmiddels is mijn blinde vertrouwen enigszins ontnuchterd, maar nog steeds is mijn … [Lees meer...] oversChatje, maak eens een tentamenvraag
Python en poëzie

Een van de interessantste Nederlanders op dit moment is ongetwijfeld Guido van Rossum, de ontwerper van de programmeertaal Python. Het is niet overdreven om te zeggen dat dit inmiddels wereldwijd de populairste programmeertaal is – een taal die vrijwel iedere programmeur wel een beetje kent. Hij is bovendien iemand die over heel veel onderwerpen goed heeft nagedacht en zijn … [Lees meer...] overPython en poëzie
Hoe intelligent is Google Translate nu echt?

Een vraag die ons al vanaf het begin van het computertijdperk bezighoudt: 'Gaat de computer ooit taal gebruiken zoals mensen dat doen?' Spreken, schrijven, vertalen? In deze aflevering spreken we taaltechnoloog Vincent Vandeghinste over hoe het automatisch vertalen ('machine translation') van teksten precies werkt, wat taalmodellen en neurale netwerken zijn, en hoe de … [Lees meer...] overHoe intelligent is Google Translate nu echt?
De domheid van computers
Ik volg de kunstmatige intelligentie (AI) inmiddels al ruim vijfendertig jaar. De geschiedenis van dat vak is vrijwel volmaakt cyclisch. Er is een technologische vooruitgang: computers worden sneller en als gevolg daarvan werken de AI-programma's weer net wat beter. Dat betere wordt vervolgens zo geïnterpreteerd alsof we het licht nu echt gezien hebben: nog één tandje erbij en … [Lees meer...] overDe domheid van computers
Wat kan een computer het vermogen om te doen leren?

Er is belangrijk nieuws in een van de heftigste taalkundige discussies van de afgelopen vijftig jaar. We doen even een experiment met het taalmachientje onder je hersenpan. Wat betekent de volgende zin? Wat geloof jij dat de actrice gisteren gekocht heeft? De vraag is nu: wat is het lijdend voorwerp van gekocht? Dat is als je Nederlands spreekt hopelijk geen ingewikkelde … [Lees meer...] overWat kan een computer het vermogen om te doen leren?
Hoe communiceren robots en dieren?

Taal en muziek worden vaak gezien als specifiek menselijke communicatieve vaardigheden. Maar ook dieren communiceren met elkaar. En robots moeten soms met mensen samenwerken en communiceren. Wat zijn overeenkomsten tussen menselijke en niet-menselijke communicatie, en wat zijn verschillen? … [Lees meer...] overHoe communiceren robots en dieren?
Eigennamen in streekromans

Dagboek van een amateur-programmeur Nu we hier zo gezellig thuis zitten, en Ewoud Sanders zo vrijgevig is geweest met een paar grote bestanden met pdf's, leek het me aardig om daar nog eens wat verder in te zoeken. Dit wordt hopelijk het begin van een serietje, want ik denk dat ik meteen iets op het spoor ben en het is misschien een aardige manier om jullie mee te laten … [Lees meer...] overEigennamen in streekromans
Computers nog niet goed met taal?
Alles overziend concluderen sommige onderzoekers dat er nog teleurstellend weinig eenheid is tussen onderzoekers die proberen op de computer de manier te modelleren waarop mensen van taal gebruiken. Is die teleurstelling terecht? Bekijk deze video op YouTubeBekijk alle filmpjes over Human Language. … [Lees meer...] overComputers nog niet goed met taal?
Schrijvende computers
Computers kunnen inmiddels over sommige onderwerpen best een aardig tekstje schrijven. Het probleem is alleen dat ze zo saai zijn. Bekijk deze video op YouTubeBekijk alle filmpjes over Human Language. … [Lees meer...] overSchrijvende computers
Computers en betekenis
Wat betekent het woord boom? Volgens een bepaalde manier van kijken wordt die betekenis bepaald door alle contexten waarin het woord boom voorkomt. Die manier van kijken blijkt goed werkbaar te maken voor een computer en geeft potentieel een scherp beeld van wat de betekenis eigenlijk is. Bekijk deze video op YouTubeBekijk alle filmpjes over Human Language. … [Lees meer...] overComputers en betekenis
Computers tuinen erin
Een computer bouwen die taal kan verstaan is één ding; een computer die taal begrijpt zoals een mens dat doet, is nog heel wat anders. Want zo’n computer moet van dezelfde dingen in de war raken als mensen. Intuinzinnen bijvoorbeeld. … [Lees meer...] overComputers tuinen erin
Elektronische taalhersenen
Neurale netwerken simuleren de werking van het brein op een computer. Ze zijn dan ook heel bruikbaar om theorieën te toetsen over de werking van taal in het brein. Kan zo'n netwerk bijvoorbeeld een taal leren zonder dat je er vantevoren kennis in stopt? … [Lees meer...] overElektronische taalhersenen
Computers als Neanderthalers
Computers zijn heel handig voor taalonderzoek. Bijvoorbeeld als je wil weten hoe apen of Neanderthalers zouden praten. En waarom het lichaam van de mens zo geschikt is voor taal. … [Lees meer...] overComputers als Neanderthalers
Aandacht als de sleutel om taal te begrijpen
Sommige van de belangrijke ontwikkelingen in de taalkunde komen uit de computertaalkunde – de discipline waar men probeert computers aan het praten, luisteren, schrijven en lezen te krijgen. Toen ik studeerde, stond het nog dicht bij wat andere taalkundigen deden, maar inmiddels heeft de technologie een grote, en eigen, vlucht genomen. Er gebeurt, desondanks of daarom, van … [Lees meer...] overAandacht als de sleutel om taal te begrijpen
Ironie. #not

Door Marc van Oostendorp De Nederlandse Twittertaal ontwikkelt een verschil tussen de hashtags #niet en #not, ontdekte ik gisteren toevallig. De eerste geeft meestal een krachtige ontkenning aan; de tweede betekent ironie. Het is niet gemakkelijk om ironie te herkennen. Dat komt doordat het een stijlfiguur is die zich als het ware verstopt: de spreker neemt terwijl hij iets … [Lees meer...] overIronie. #not
Afwezige verschillen v/m in literaire schrijfstijl? Een snufje nuance
Door Corina Koolen Toen ik de afgelopen week promoveerde, stond mijn onderzoek beschreven in de grote kranten. De Volkskrant, NRC, nrc.next en Het Parool besteedden er aandacht aan. Dat waren mooie stukken; ik vind het uiteraard belangrijk dat mijn onderzoek benaderbaar is en dat het iets toevoegt aan het publieke debat. Aan de andere kant is er nu één ding dat blijft … [Lees meer...] overAfwezige verschillen v/m in literaire schrijfstijl? Een snufje nuance
Praten met robots dankzij Google
Door Lucas Seuren De afgelopen decennia heb ik regelmatig claims gezien dat computers spoedig probleemloos kunnen communiceren met mensen, en dat we het niet eens meer door zullen hebben als we met een AI praten. Maar tot op heden waren dialoogsystemen absoluut niet in staat om de Turingtest te doorstaan; we maken nog altijd eenvoudig onderscheid tussen een menselijke … [Lees meer...] overPraten met robots dankzij Google
De mens is een dier dat samenwerkt

Door Marc van Oostendorp Je zit in de auto, het is midden in de nacht, de reis is nog lang en je wil nu tanken. Je vraagt aan de spraakcomputer: "waar is hier in de buurt een benzinestation?" Vervelend is dan als die computer een lijst van 16 bezinestations geeft die 'in de buurt' zijn, hoewel ze deels niet eens aan dezelfde weg liggen (ze liggen wel in een straal van 10 km om … [Lees meer...] overDe mens is een dier dat samenwerkt
Literaire stijl als een computerkunstje

(Persbericht Radhoud Universiteit) Is de creatie van een uniek literair oeuvre voorbehouden aan zwoegende schrijvers of kan een computer de klassiekers imiteren? In het project ‘Writers in the Cloud’ schrijven bezoekers van het Erasmusgebouw van de universiteit met behulp van taaltechnologie een tekst in de trant van schrijvers als Couperus, Grunberg of Bervoets. Het project … [Lees meer...] overLiteraire stijl als een computerkunstje
Oplossing voor taalkundig probleem van 100 jaar oud

(Persbericht Radboud Universiteit) Wist je dat in iedere taal het meest voorkomende woord ongeveer twee keer zo vaak voorkomt als het op een na meest voorkomende woord? Deze wet genaamd ‘Zipf’s law’ is al ruim een eeuw oud, maar tot nu toe lukte het wetenschappers niet om het verschijnsel precies te verklaren. Taalwetenschapper Sander Lestrade van de Radboud Universiteit … [Lees meer...] overOplossing voor taalkundig probleem van 100 jaar oud
Perplexiteit als venster op de taal
Door Marc van Oostendorp Een zin is een meerdimensionaal object. Hij bestaat uit woorden, die op hun beurt minstens twee dimensies hebben: een klankvorm ('spruitje') en een betekenis ('klein groen koolachtig bolletje met een bittere smaak'). En die woorden staan ook nog eens in een bepaalde syntactische relatie tot elkaar. Als je naar een zin, een willekeurige zin, luistert, … [Lees meer...] overPerplexiteit als venster op de taal
Hoe werkt Google Translate?
Door Marc van Oostendorp Vorige week kondigde Google Translate een nieuwe, verbeterde versie aan van de vertalingen van (onder andere) het Nederlands naar het Engels en omgekeerd. Hoe is de nieuwe versie verbeterd? En wat kan er nóg beter? Ik vroeg het aan Antal van den Bosch, de directeur van het Meertens Instituut en zelf als hoogleraar Taal- en Spraaktechnologie ook ervaren … [Lees meer...] overHoe werkt Google Translate?
Herken de herkomst aan de taal: goed idee?
Door Sterre Leufkens Hoe weet je waar iemand vandaan komt? Zie je dat aan zijn kleding? Aan zijn haarkleur? Of is bepaald gedrag bepalend? Dat lijkt toch allemaal vrij oppervlakkig. Een van de beste manieren om iemands herkomst te bepalen lijkt toch zijn taal te zijn. Op basis van dat principe proberen immigratiediensten in binnen- en buitenland al jarenlang om te bepalen of … [Lees meer...] overHerken de herkomst aan de taal: goed idee?