Door Instituut voor de Nederlandse Taal
 Dinsdag 9 april heeft het Instituut voor de Nederlandse Taal een nieuwe versie van de OpenSoNaR webapplicatie gelanceerd, waarmee je kunt zoeken in grote hoeveelheden geschreven en gesproken Nederlands. De applicatie geeft toegang tot data uit het SoNaR-corpus, een verzameling geschreven teksten van meer dan 500 miljoen woorden, en het Corpus Gesproken Nederlands (CGN), een verzameling van 900 uur Nederlandse spraak.
Dinsdag 9 april heeft het Instituut voor de Nederlandse Taal een nieuwe versie van de OpenSoNaR webapplicatie gelanceerd, waarmee je kunt zoeken in grote hoeveelheden geschreven en gesproken Nederlands. De applicatie geeft toegang tot data uit het SoNaR-corpus, een verzameling geschreven teksten van meer dan 500 miljoen woorden, en het Corpus Gesproken Nederlands (CGN), een verzameling van 900 uur Nederlandse spraak.
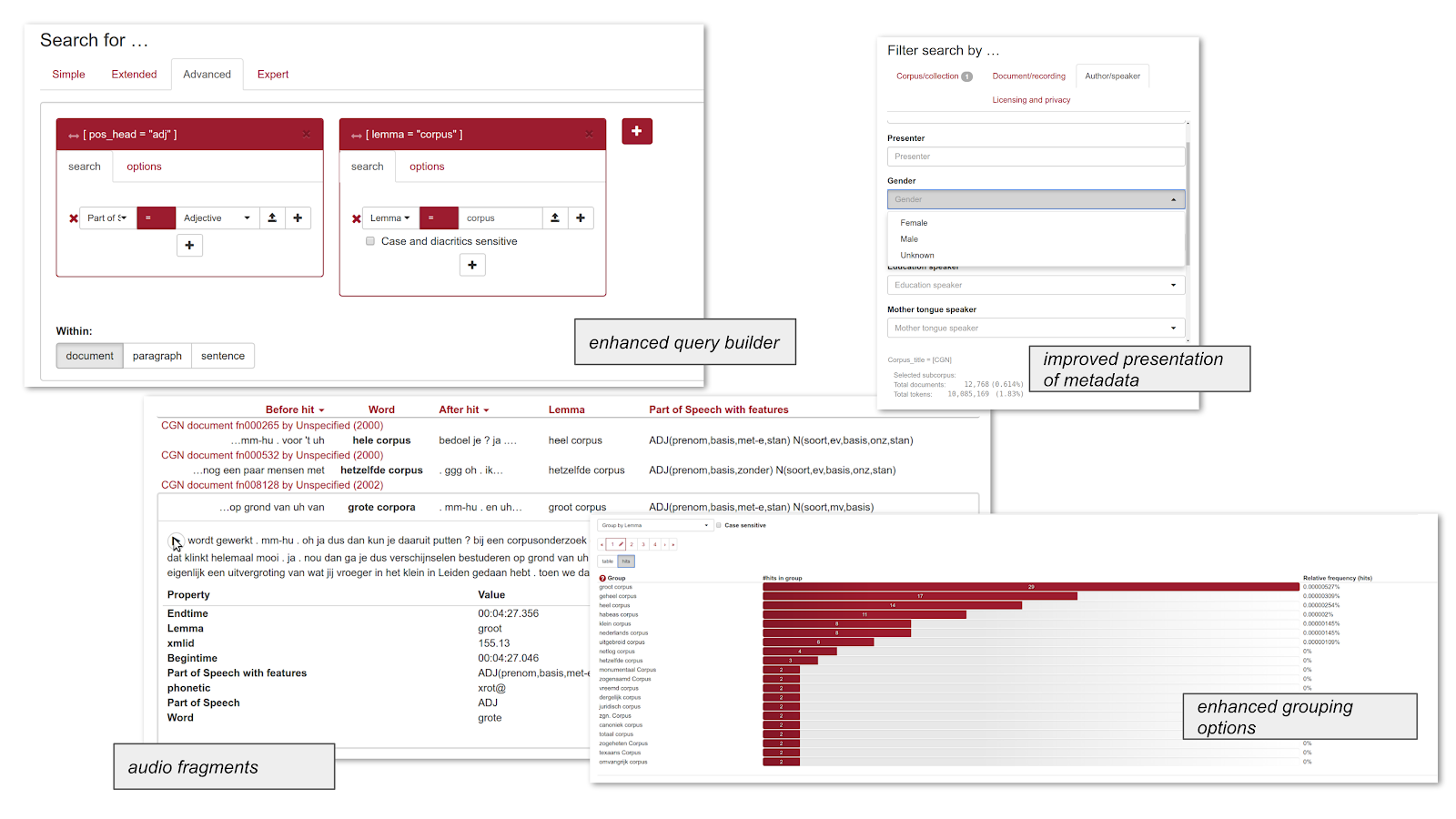
De nieuwe webapplicatie maakt het mogelijk om te zoeken in alle data van de twee verzamelingen (corpora). De grote hoeveelheden tekst zijn voorzien van extra taalkundige informatie zoals woordsoort en lemma, en bovendien zijn van het Corpus Gesproken Nederlands ook de geluidsfragmenten te beluisteren. In de applicatie kun je eenvoudig zoeken op een woord, of een complexere zoekactie doen door te selecteren op een specifieke annotatie of door reguliere expressies te gebruiken. Daarnaast is het mogelijk om de zoekresultaten op te slaan, de zoekgeschiedenis te raadplegen en frequentielijsten te bekijken.
Het CGN en SoNaR
 Het Corpus Gesproken Nederlands (CGN) is een verzameling van 900 uur (bijna 9 miljoen woorden) hedendaags Nederlandse spraak, afkomstig van Vlamingen en Nederlanders. De spraakfragmenten (spontaan en voorbereid) zijn voorzien van diverse transcripties (o.a. orthografisch, fonetisch) en annotaties (syntactisch, POS-tags). Het SoNaR-corpus bevat meer dan 500 miljoen woorden tekst afkomstig uit uiteenlopende domeinen en genres. Alle teksten werden automatisch getokeniseerd, ge-POS-tagd en gelemmatiseerd. Ook de named entities werden gelabeld.
Het Corpus Gesproken Nederlands (CGN) is een verzameling van 900 uur (bijna 9 miljoen woorden) hedendaags Nederlandse spraak, afkomstig van Vlamingen en Nederlanders. De spraakfragmenten (spontaan en voorbereid) zijn voorzien van diverse transcripties (o.a. orthografisch, fonetisch) en annotaties (syntactisch, POS-tags). Het SoNaR-corpus bevat meer dan 500 miljoen woorden tekst afkomstig uit uiteenlopende domeinen en genres. Alle teksten werden automatisch getokeniseerd, ge-POS-tagd en gelemmatiseerd. Ook de named entities werden gelabeld.
OpenSoNaR is gratis toegankelijk met een gebruikersaccount van een universiteit, of met een CLARIN-account. De applicatie is ontwikkeld door een team van het Instituut voor de Nederlandse Taal, Tilburg University en de Radboud Universiteit, binnen de projecten CLARIN-NL en CLARIAH.
Vanuit CLARIAH zullen bij voldoende belangstelling op nog nader aan te kondigen tijdstippen cursussen gegeven worden in het gebruik van deze en andere corpora. Belangstellenden kunnen zich opgeven door te mailen naar clariah@huygens.knaw.nl.
- Ga naar OpenSoNaR
- Meer informatie over het Corpus Gesproken Nederlands
- Meer informatie over het SoNaR-corpus
- Lees meer over CLARIN en CLARIAH
Jammer dat het geen algemeen toegankelijke database is zonder inlogaccount.
Al enkele keren gebruikt voor variatieonderzoek België-Nederland, en heel tevreden met de resultaten. Ik ben vooral blij dat het CGN er nu bij zit, dat is echt een verrijking. Zijn er intussen plannen om de databanken te updaten?