Door Marc van Oostendorp
Een interessante en nog niet helemaal correlatie in de taalwetenschap: hoe meer sprekers een taal heeft, hoe eenvoudiger de grammatica. Veel talen die door kleine groepjes indianen worden gesproken hebben een heel ingewikkelde zinsbouw; het Engels en het Chinees steken daar enigszins bleek bij af. Aan de andere kant hebben talen als het Engels veel meer woorden dan kleinere talen, en zijn in die zin dus eenvoudiger.
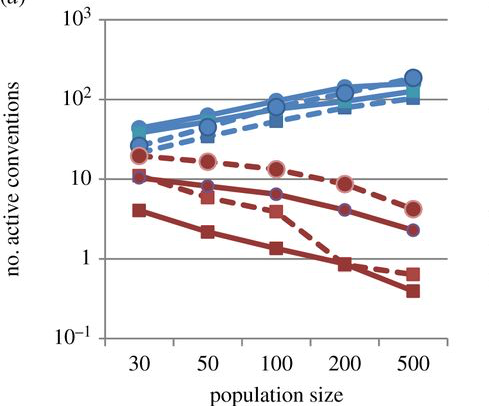
In een nieuw artikel in Proceedings of the Royal Society B schrijven drie psychologen dat ze mogelijk een oplossing hebben gevonden voor het raadsel: grammatica is moeilijk te leren en woorden zijn gemakkelijk te leren. Om te laten zien wat voor effect dat heeft, bouwden ze een computermodel dat bestond uit een verzameling botjes. Die konden nieuwe ’taalconstructies’ bedenken of deze van andere botjes leren. Sommige constructies waren gemakkelijk – de botjes hadden ze geleerd zodra ze ze hoorden – en andere waren moeilijk – ze hadden twee keer horen nodig.
Wat bleek: aan het eind van een sessie hadden groepen van botjes veel eenvoudige constructies en weinig complexe in hun gezamelijke repertoire, en kleine groepen hadden relatief veel meer ingewikkelde.
Inherent lastiger
Het computerexperiment zit vernuftig in elkaar, maar ik weet eigenlijk niet wat we er precies mee moeten. Er is een bepaald genre wetenschappelijke artikelen waarin men heel nauwkeurig en precies een heel klein experiment doet om daar dan in de inleiding en de conclusie allerlei idioot grootse conclusies aan te verbinden. In dit geval wordt er beweerd dat dit misschien wel van alles en nog wat zegt over de manier waarop culturele verschijnselen zich verspreiden.
En zelfs dat dit iets zegt over taal is niet zo duidelijk. Dat woorden ‘gemakkelijk’ te leren zijn en grammatica ‘moeilijk’, maken de onderzoekers eigenlijk niet duidelijk. Voor de interpretatie van het experiment (waarin alleen sprake is van ‘moeilijke’ en ‘gemakkelijke’ dingen, die verder precies dezelfde vorm hebben) is dat wel degelijk van belang, maar in ieder geval bij kinderen is er geen enkele aanwijsbare reden om te denken dat syntactische reden inherent lastiger zijn dan woorden. Wel lijkt me duidelijk dat je van woorden nu eenmaal meer nodig hebt dan van grammaticale constructies.
Complex
Bovendien is helemaal niet zo duidelijk dat de correlatie voor de grammatica precies zo is als de auteurs schijnen te denken: het gaat volgens sommige onderzoekers niet om het aantal sprekers, maar om de mate van openheid van de samenleving: hoe makkelijker men vreemdelingen welkom heet, hoe eenvoudiger de taal. Dat verband wordt dan veroorzaakt doordat volwassenen grammatica inderdaad lastiger te vinden dan kinderen. Wanneer een taal alleen moedertaalsprekers heeft kan ze zich dus meer complexiteit veroorloven. (Indirect is er dan natuurlijk wel een verband, omdat er een relatie is tussen de openheid van een taalgemeenschap en het aantal sprekers van de desbetreffende taal.)
Voor de woordenschat is de correlatie er vermoedelijk juist wel rechtstreeks een met grootte, en vrij triviaal verklaarbaar: hoe meer mensen een taal gebruiken, hoe meer verschillende dingen ze met elkaar willen bespreken. Een verschil is ook dat iedereen wel zo’n beetje de hele verzameling regels voor zinsbouw kent, terwijl omvangrijke delen van de woordenschat van een ‘grote’ taal alleen bedoeld zijn voor specialisten.
Wetenschappers maken modellen van de werkelijkheid. Modellen zijn per definitie vereenvoudigingen. De werkelijkheid – in dit geval die van mensen die met elkaar praten – is zo complex, daar valt eigenlijk niet aan te rekenen. Maar in dit geval is de relatie tussen model en werkelijkheid zoek. Het is niet duidelijk waarom de zaken die in de computers zijn gestopt zouden corresponderen met woorden, met grammaticale zinsconstructies, met taalgemeenschappen.
Curieus.
Laat een reactie achter