Door Marc van Oostendorp
 Een van de problemen voor vertaalcomputers was tot nu toe altijd dat er zoveel talen zijn. Je kunt jaren besteden aan een computer die goede vertalingen maakt van het Frans in het Engels, en dan vele jaren voor een computer die Russisch in het Engels vertaalt, maar dan heb je het Frans en het Russisch nog niet aan elkaar gekoppeld. Dat probleem lijkt nu op een interessante manier te worden opgelost door het team achter Google Translate, die er deze week een artikel over publiceerden.
Een van de problemen voor vertaalcomputers was tot nu toe altijd dat er zoveel talen zijn. Je kunt jaren besteden aan een computer die goede vertalingen maakt van het Frans in het Engels, en dan vele jaren voor een computer die Russisch in het Engels vertaalt, maar dan heb je het Frans en het Russisch nog niet aan elkaar gekoppeld. Dat probleem lijkt nu op een interessante manier te worden opgelost door het team achter Google Translate, die er deze week een artikel over publiceerden.
Bij iedere taal die je toevoegt wordt het probleem ingewikkelder. Drie talen (Frans, Russisch, Engels) betekent drie paren talen (Frans-Engels, Frans-Russisch, Engels-Russisch); maar als je een vierde aan de verzameling toevoegt (Nederlands) worden dat er ineens zes (Nederlands-Frans, Nederlands-Engels, Nederlands-Russisch komen erbij). En bij een vijfde taal komen er vier taalparen bij, enzovoort. Omdat vertalen van het Russisch naar het Nederlands nog iets anders is dan vertalen van het Nederlands naar het Russisch, moet je die aantallen eigenlijk nog verdubbelen. Hoe meer talen er al zijn, hoe meer werk het wordt om er nog een aan toe te voegen.
Ontwerpen
In de lange geschiedenis van de vertaalcomputer is daar ook ooit wel een oplossing voor bedacht: de tussentaal (interlingua), een abstracte taal die ‘in het midden staat’ en die de betekenis van de zin op de een of andere manier opslaag. Je vertaalt van iedere taal alleen naar die interlingua en terug. Als je van het Engels naar het Frans vertaalt, vertaal je eigenlijk eerst van het Engels naar de interlingua en daarna van de interlingua naar het Frans. Het voordeel is: je hoeft als je een nieuwe taal toevoegt alleen een module toe te voegen om naar de interlingua te vertalen. Bij heel veel talen wordt dat efficiënt.
Het probleem van dat interlingua-systeem is echter altijd geweest: hoe moet die interlingua er dan uitzien? Wat moet dat voor magisch systeem zijn dat de ‘betekenis’ van een zin opslaat op een soort neutrale manier? Hoe kun je zoiets ontwerpen?
Daarop zijn dit soort pogingen altijd stukgelopen en het populairste automatische vertaalproject aller tijden, Google Translate, vertaalt enkele tientallen talen, maar doet dat steeds (min of meer) rechtstreeks, ook al betekent dat er met een groot aantal taalparen moet worden gewerkt. (Al schijnt er soms wel een weggetje te worden afgesneden en wordt sommige Jiddisj ‘via het Duits’ vertaald, omdat het Duits zoveel op Jiddisj lijkt en dus als een soort interlingua kan werken.)
Japans naar Koreaans
Maar sinds een paar maanden schakelt men over naar een nieuw systeem, waarin de computer zelf probeert uit te vinden hoe hij tussen twee talen moet vertalen: je voert hem een heleboel teksten met vertalingen en het systeem probeert daar zelf de patronen in te ontdekken. Ik schreef er hier eerder over.
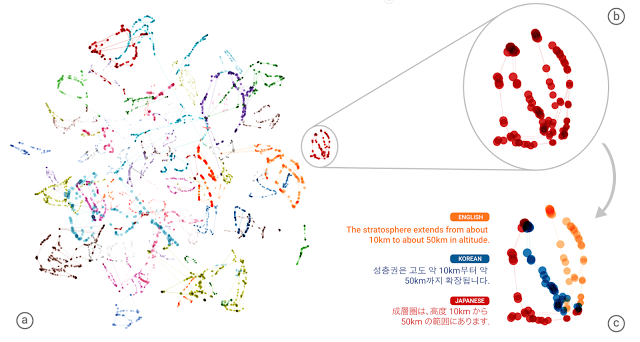
In hun nieuwe artikelen beschrijven sommige van de makers van de ‘nieuwe’ Google Translate een nieuwe ontdekking die ze deden terwijl ze het systeem aan het maken waren: het toevoegen van talen blijkt een stuk eenvoudiger. Toen ze het systeem hadden getraind om van het Japans naar het Engels te vertalen, en daarna om van het Engels naar het Koreaans te vertalen. Toen de computer dat eenmaal kon bleek hij zonder enige aparte training ook redelijk van het Japans naar het Koreaans te kunnen vertalen.
De computer had zelf een tussentaal gevonden!
Kleine beetjes
De auteurs leggen uit dat het door de eigenzinnige en ingewikkelde manier waarop computers te werk gaan, nog niet gemakkelijk is om te bepalen wat die interlingua precies is (hoeveel hij, in dit geval, bijvoorbeeld lijkt op het Engels).
Maar het opent natuurlijk interessante perspectieven. Dat geldt vooral voor kleine talen, waarvoor automatisch vertalen misschien wel het nuttigst is, en waarvoor tegelijkertijd te weinig materiaal is om de computer te trainen: er zijn misschien wat vertalingen van en naar het Engels en nog een handjevol van en naar het Russisch, maar die zijn allebei niet genoeg om de taal echt te kunnen toevoegen. Maar als de computer echt een interlingua heeft gedefinieerd kun je die kleine beetjes misschien bij elkaar voegen om tot een goede vertaling te komen.
Laat een reactie achter